Confiabilidad
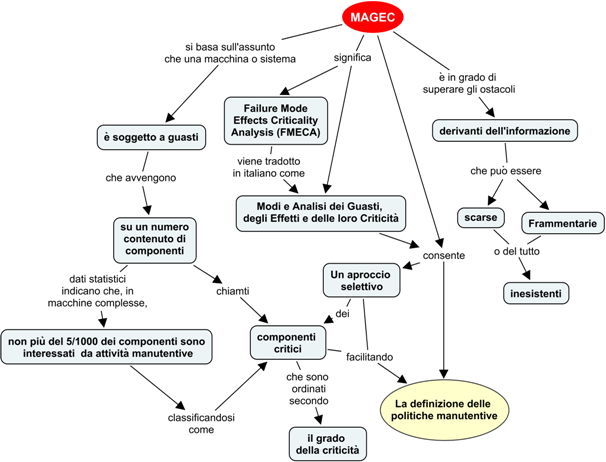
Reliability Centered Maintenance e Manutenzione su Condizione e Predittiva
Por Luis Felipe Sexto
Versiòn en italiano
Introduzione della Manutenzione su Condizione e predittiva come parte di un processo di Reliability Centered Maintenance.
INGENIERÍA DE LA MANTENIBILIDAD

Por Luis Felipe Sexto
MUCHO SE COMENTA SOBRE LA CONFIABILIDAD Y LA DISPONIBILIDAD, y un concepto estratégico tal parece que mereciera considerarse en un segundo plano, pero resulta que no es segundo ni puede serlo. Me refiero a la mantenibilidad. Lo cierto es que la ingeniería de la mantenibilidad aborda una buena parte de todo lo concerniente al mantenimiento de la funcionalidad de un sistema por parte del usuario y estimula, propone y aplica técnicas para su cuantificación, evaluación, predicción y mejora. Ya se conoce que la confiabilidad inherente de cualquier sistema queda determinada por sus diseño, sin embargo, su confiabilidad en el contexto queda afectada, entre otras cosas, por la mantenibilidad y aquí se cruzan y complementan estas dos disciplinas, incidiendo ambas sobre la disponibilidad. La mantenibilidad se asocia con la capacidad de recuperar las funciones previstas de un activo físico cuando se efectúan, sobre él, tareas de mantenimiento siguiendo procedimientos establecidos. Queda evidenciado que cualquier sistema puede perder sus funciones y que, a su vez, este hecho puede suceder de manera progresiva o abrupta. Esta característica establecida por el fenómeno de la degradación que, por diversas causas, sufre cualquier sistema impone la necesidad de la existencia de la ingeniería de la mantenibilidad. incluso los sistemas clasificados cono no reparables, se someten al reino de la mantenibilidad al establecerse para ellos acciones preventivas de sustitución. ¿Y cómo se manifiesta este concepto? Lo tenemos en la práctica diaria. Una parte importante de las tareas de mantenimiento preventivo que se realizan, buscan disminuir o eliminar la ocurrencia de fallos funcionales. Por tanto, de lograrlo, mantienen o mejoran la confiabilidad. Contrariamente, un exceso de tareas de mantenimiento traen como efecto directo e inmediato una caída de la confiabilidad, al introducir desperfectos y fallos en los sistemas que se intervienen (para el último caso pensemos en estos tres conocidos estados después de intervenciones: 1-mejor que antes de fallar, pero peor que nuevo; 2-tan malo como antes de fallar o 3-peor que antes de fallar). En general se acepta que los elementos menos confiables deberán ser los más mantenibles. Esto es absolutamente lógico en un proceso de asignación de mantenibilidad. Si la confiabilidad inherente es baja, entonces la capacidad de recuperar la funcionalidad debería ser elevada. Y esto es pura mantenibilidad inherente como medio de ajuste y compensación a las flaquezas de la confiabilidad. Sin embargo, los tiempos para realizar las tareas de mantenimiento muchas veces deberán ser asignados en base a la experiencia previa y criterios de expertos ya que la mantenibilidad no es tan fácil asignarla con precisión sin considerar el contexto operacional. La estimación del Tiempo Medio de Mantenimiento Correctivo Activo (Mean Active Corrective Maintenance Time, MACMT), del Tiempo Medio Entre Acciones de Mantenimiento (Mean Time Between Maintenance, MTBM), del Tiempo Medio Entre Sustituciones (Mean Time Between Replacement, MTBR), del Tiempo Medio de Recuperación (Mean Time To Restore, MTTR), se realiza precisamente empleando como base los datos de confiabilidad y la información generada por la experiencia. La mantenibilidad tiene un peso principal en lo que se puede lograr en relación con la confiabilidad real de los sistemas que se explotan. Por ello, sus plataformas de planificación se deben tanto a lo que sucede realmente, al contexto operacional, al criterio de expertos, a la experiencia previa, a las técnicas de diagnóstico y tareas según la condición y predictivas. No obstante, la norma British Standard BS 6542-2 es una guía para los estudios de mantenibilidad durante la fase de diseño, quedando al descubierto que se trata de un concepto que en buen grado de intencionalidad queda establecido, como la confiabilidad, desde las fases tempranas del producto al asociarse a una característica inherente relativa a la capacidad de ser recuperada la funcionalidad dado un uso previsto.Con todo esto, ¡mucha atención al asignar objetivos únicamente en función de la confiabilidad! La mantenibilidad en el contexto exige sus espacios conscientes y esta dotada de personalidad propia tanto como la confiabilidad y a veces...
LESSENZA DELLA RELIABILITY CENTERED MAINTENANCE
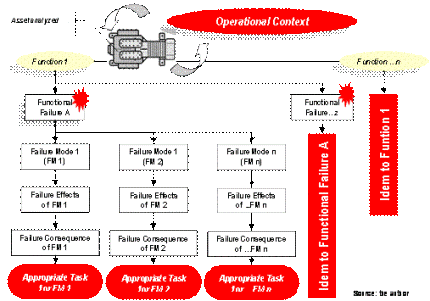
Per Luis Felipe Sexto (fragmento. Artículo completo en el número de abril/2007. Revista oficial de la AIMAN)
L’obiettivo principale di un processo di Reliability Centered Maintenance (RCM) consiste nel garantire che la funzionalità dei sistemi in un ben delimitato contesto operativo sia sempre allineata con quella richiesta dal proprietario o dall’utente dei sistemi stessi. Per soddisfare tale finalità, solitamente si adotta una metodologia proporzionata alle conseguenze che comporterebbe il tipo di guasto e che ovviamente ha riflessi notevoli sulle procedure di manutenzione necessarie per garantire la funzionalità del sistema aziendale di riferimento che si sta analizzando. Non tutti i processi che si qualificano RCM lo sono veramente, ma soltanto quelli che soddisfano la normativa SAE JA 1011: 1999 dove sono definiti i requisiti che un processo di manutenzione deve soddisfare affinché possa essere chiamato “processo RCM”. I modi di guasti sono definibili come gli eventi causa dei danni medesimi con la conseguente perdita di funzionalità (guasti funzionali) del sistema, apparecchio o processo oggetto di analisi. Significa cioè che ragioni di carattere tecnico od umano, come per esempio errori umani, possono portare a uno stato di non conformità, totale o parziale, dell’obiettivo richiesto dal processo analizzato. Da qui, nasce l’importanza della loro identificazione e analisi. Questo passaggio rappresenta l’inizio del processo RCM, che richiede la descrizione degli effetti di ogni modo di guasto del sistema oggetto dell’analisi. Si completa così la prima fase del processo RCM che altro non è che l’applicazione di un FMEA (Failure Mode and Effect Analysis). Nella seconda fase si passa ad analizzare l’importanza di ogni modo di guasto e si definiscono le possibili attività di manutenzione. A sovrintendere la fase di scelta delle possibili attività di manutenzione vi sono due condizioni che devono essere soddisfatte congiuntamente: oltre a essere tecnicamente attuabili, devono anche essere sostenibili, ovvero deve valer la pena di realizzarle in base alle conseguenze che deriverebbero dall’eventuale guasto. Gli elementi appena esposti determinano se l’attività di manutenzione è appropriata o meno (appropriate task) alla tipologia di guasto .Vedasi figura. I guasti non sono importanti di per sé, ma si per il fatto delle conseguenze che potrebbero generare. Queste conseguenze siano accettabili per l’azienda o meno? La RCM individua quattro categorie di conseguenze che possono derivare da un modo di guasto, permettendo così di valutare l’importanza dello stesso. In ordine di priorità, abbiamo: conseguenze per la sicurezza; per l’ambiente; per l’operazione e quelle denominate come non operazionali, che sono vincolate con il costo dell’intervento manutentivo. In accordo con la conseguenza principale che derivano dal modo di guasto che si sta analizzando, si potrà seguire un processo logico-decisionale per proporre l’attività —predittiva, su condizione, preventiva ciclica, di modifica o di manutenzione a guasto— che lo possa gestire, per tentare di minimizzare o eliminare la suddetta conseguenza. Ogni modo di guasto esaminato dovrà disporre di un’attività per gestirlo. Inizialmente, l’attività comporta la scelta di una frequenza di esecuzione della manutenzione e di un responsabile che ne garantisca l’esecuzione. Nella figura viene sintetizzata la logica elementare del processo RCM una volta scelto il sistema di riferimento; si presuppone cioè una preventiva analisi del sistema e della criticità.
RCM, UNA VISIÓN DE ABAJO PARA ARRIBA
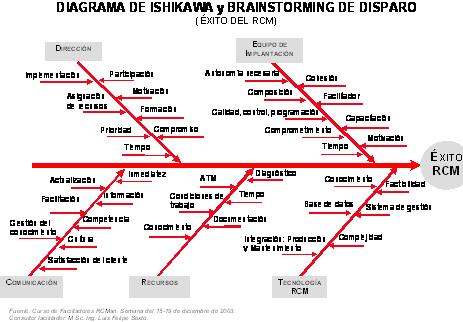
Por Luis Felipe Sexto
La figura representa el diagrama de Ishikawa (Causa-Efecto) elaborado por los participantes a un seminario de facilitadores, para la implementación piloto de un proceso de Mantenimiento Centrado en la Confiabilidad (RCM). En el diagrama se identifican un conjunto de categorías y factores que pueden contribuir a lograr una implantación con éxito (o fracaso) del RCM en las diferentes entidades de una gran organización nacional. Resulta importante la reflexión profunda y objetiva relacionada con la forma en que impactan (positiva o negativamente) estos elementos identificados, de acuerdo al modelo de actuación que hasta el momento se lleva en la organización. Especial énfasis hicieron los participantes en esta sesión de trabajo, relativo a los elementos de la categoría Comunicación y Dirección. Se reconocen dificultades en los procesos de comunicación percibidas e identificadas en la base. Estas dificultades conciernen a todos los niveles de la organización (entre dirección media y base; dirección media y alta dirección). EL diagrama Causa Efecto refleja claramente que la meta de introducir el RCM como estrategia es un asunto que involucra a toda la organización y que el éxito está estrechamente vinculado con el compromiso y la comprensión de la necesidad del implementar procesos de RCM como respuesta a la estrategia de ver el mantenimiento como negocio y como necesidad de mantener los activos físicos y mejorar la eficacia y la eficiencia de la operación (y del propio mantenimiento). Mucha sabiduría emana de las personas “de abajo” cuando se les ofrece la oportunidad de opinar y proponer soluciones a las barreras que se oponen al avance. Si no lo cree, observe lo que se evidencia en el diagrama. Los facilitadores lograron identificar treinta y siete factores distribuidos en cinco categorías básicas, que se relacionaban con una implementación exitosa (o no) del RCM en su organización. Todo esto en poco más de una hora con la ayuda de un consultor facilitador y echando mano del brainstorming de disparo para asistir al diagrama de Ishikawa con mejor eficiencia. Una vez identificados los factores que afectan, en un primer acercamiento, es posible determinar cuáles son críticos para el éxito del proceso y actuar en consecuencia. No obstante, sería bueno recordar que del 70 al 80% de los problemas de cualquier organización son responsabilidad de la dirección, debido a que son controlables por ella. Analice si no. Liderazgo colectivo es el suceso de orden. ¿Está de acuerdo?
CONFIABILIDAD EN EL AIRE: ¿CON QUIÉN SE VUELA MÁS SEGURO?
Por Luis Felipe Sexto
¡Más rápido, más alto, más lejos y más seguros! Es el paradigma de las líneas aéreas en el mundo. Sin embargo por diversas razones de tipo técnicas, gerenciales, económicas o por ciscunstancias particulares el desempeño en seguridad de vuelo varía de una aereolínea a otra. Así por zonas geográficas tenemos que las tasas de fallos catastróficos más alta pertenecen en Norteamérica (USA y Canada) a ValuJet/AirTran con 5,88. En el área del Caribe y Sudamérica, Cubana de Aviación y Aeroperú ostentan los mayores indicadores negativos con 24 y 16,7 respectivamente. En el viejo continente el peor valor lo muestra Turkish Airlines (THY) con 7,30. En Africa y medio oriente se encuentran Royal Jordanian y EgyptAir con tasas de 8,82 y 8,0 por su orden. En Australia y Asia se encuentran con menores desempeños China Airlines y Air India con sendas tasas de accidentes de 10,2 y 6,82.
¿Pero en esencia que significan estos números?
La tasa de fallos pude expresarse de diversas maneras. Normalmente se obtiene para cualquier sistema, como número de fallos por unidad de tiempo, pero también es posible, para los fines particulares de reflejar la tasa de fallos castastróficos, definirla como Tasa de Accidentalidad (TA) como se presenta en la ecuación (1):
TA=Eventos fatales/Número de vuelos (1)
En la siguiente tabla se representan 60 aereolíneas de todos los continentes pero ordenadas en orden decreciente de su tasa de accidentes. Lo que significa que, de la muestra de líneas aéreas, All Nippon, Delta Air Lines/Connection y British Airways son las que lideran el aspecto de seguridad en el aire.
60 | Cubana | 30 | Royal Air Moroc |
59 | Aeroperu | 29 | Saudi Arabian Airlines |
58 | Air Zimbabwe | 28 | KLM |
57 | China Airlines | 27 | Swissair |
56 | Royal Jordanian | 26 | Varig |
55 | EgyptAir | 25 | Aerolineas Argentinas |
54 | Turkish Airlines (THY) | 24 | Air France |
53 | Air India | 23 | Tap Air Portugal |
52 | ValuJet/AirTran | 22 | Malaysia Airlines |
51 | Korean Air | 21 | British Midland |
50 | Nigeria Airways | 20 | Cathay Pacific |
49 | Pakistan International | 19 | Iberia |
48 | Indian Airlines | 18 | Alitalia |
47 | Philippine Airlines | 17 | Alaska Airlines |
46 | Garuda Indonesia | 16 | Trans World Airlines/Express |
45 | LAN Chile | 15 | Braathens SAFE |
44 | Ethiopian Airlines | 14 | Air New Zealand |
43 | Midwest Express Airlines | 13 | Air Canada |
42 | Air Afrique | 12 | Continental Airlines/Express |
41 | VASP | 11 | South African Airways |
40 | Avianca | 10 | American Airlines/Eagle |
39 | Kenya Airways | 9 | USAirways/Express (USAir) |
38 | Thai Airways International | 8 | Mexicana Airlines |
37 | Iran Air | 7 | United Airlines/Express |
36 | Transbrasil | 6 | Aloha Airlines |
35 | Japan Airlines | 5 | Northwest Airlines/Airlink |
34 | SilkAir/Singapore Airlines | 4 | Lufthansa |
33 | Aeromexico | 3 | British Airways |
32 | Asiana | 2 | Delta Air Lines/Connection |
31 | Olympic Airways | 1 | All Nippon |
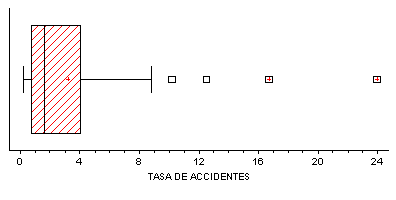
En la figura se presenta el gráfico de Caja y Bigotes para representar la TASA DE ACCIDENTES, considerando 60 aerelíneas de todos los continentes.
Un gráfico de Caja y Bigotes es una buena herramienta para mostrar varios aspectos de una muestra de datos. La parte rectangular del gráfico se extiende desde el cuartil inferior hasta el cuartil superior, cubriendo la mitad central de la muestra. La línea central dentro de la Caja muestra la localización de la mediana de la muestra. El signo + indica la localización de la media de la muestra.
Los bigotes se extienden desde la caja hasta los valores mínimo y máximo de la muestra, excepto los puntos externos o los puntos externos lejanos, los cuales se representan por separado. Los puntos externos son los que quedan a más de 1.5 veces el rango intercuartílico por encima o por debajo de la caja y se representan como pequeños cuadrados. Los puntos externos lejanos son los que quedan a más de 3.0 veces el rango intercuartílico por encima o por debajo de la caja y se representan como pequeños cuadrados con el signo + en su interior. En este caso, hay 2 puntos externos (correspondientes a Air Zimbabwe y China Airlines) y 2 puntos externos lejanos (correspondientes a Cubana de aviación y Aeroperú). La presencia de puntos externos lejanos indica, en este caso, valores atípicos.
CUBANA DE AVIACIÓN ha tenido 13 eventos catastróficos, pero para el cálculo de la tasa de accidentalidad sólo son válidos 8, dado que no se consideran desastres aéreos provocados por atentados o actos terroristas. Desde el primer reporte en 1951, hasta la fecha considerada de la estadística (diciembre de 2004), han fallecido unas 524 personas en accidentes aéreos ocasionados por aviones de CUBANA.
CONCLUSIONES
- De las líneas aéreas analizadas la de mayor confianza es ALL NIPPON con una tasa de accidentes igual a 0,22. Es decir, un accidente en 4, 64 millones de vuelos.
- La aereolínea con mayor Tasa de Accidentes es CUBANA DE AVIACIÓN con una tasa igual a 24. Lo que significa un total de 8 desastres en 0,33 millones de vuelos. Este resultado no incluye los eventos desatados a causa de actos terroristas.
- Con 8 eventos desastrosos se encuentran también: Philippine Airlines en 1,71 millones de vuelos. Garuda Indonesia en 1,96 millones de vuelos y USAirways/Express (USAir) con 55,5 millones de vuelos.
- USAirways/Express (USAir) es, con creces, la línea aérea con mayor número de vuelos con 55,5 millones.
- INDIAN AIRLINES es la aereolínea con mayor número de eventos desastrosos con 12, pero en 2,5 millones de vuelos.
- Le siguen en valores absolutos de eventos desastrosos American Airlines con 10 y United Airlines/Express con 9, en 17 y 18 millones de vuelos respectivamente.
- Se recomienda consultar el sitio http://www.airdisaster.com/ si se desea más información descriptiva, e incluso algunos reportes oficiales de análisis, sobre desastres aéreos.
- Para más detalles sobre el contenido completo de este trabajo o los fragmentos expuestos en el blog del análisis estadístico sobre accidentes aéreos, consultar con el autor.
ANÁLISIS DE LA CONFIABILIDAD HUMANA (HRA)

Por Luis Felipe Sexto
Mientras preparaba la primera versión del artículo “Catastrofes , ni tan inesperadas, ni tan inevitables”, publicado inicialmente por Bohemia en 1999 ―la revista, ya casi centenaria y de interés general, más antigua de América latina― fui comprendiendo que no era casual que la mayoría de los ejemplos, de fallos catastróficos analizados, tenían un denominador común: los errores humanos...¡Y valga la redundancia!
Desde una perspectiva estrictamente conceptual y simplificada, la confiabilidad inherente de un sistema se relaciona con el número de fallos que ocurren en determinado tiempo y bajo especificas condiciones de operación. Por su parte, la confiabilidad humana se vincula con el número de errores que se cometen en un tiempo igualmente determinado y, nuevamente, bajo especificas condiciones de trabajo. Por ello, la confiabilidad en el contexto de operación de un sistema, suma los modos de fallos que ocurren por la naturaleza del sistema en interacción con su ambiente (llamémosles modos de fallo técnicos) y aquellos determinados por las personas que interactúan con el sistema (llamémosles modos de fallo humanos o, sencillamente, errores).
La confiabilidad humana, según documentos de la CE, se define como "el cuerpo de conocimientos que se refieren a la predicción, análisis y reducción del error humano, enfocándose sobre el papel de la persona en las operaciones de diseño, mantenimiento, uso y gestión de un sistema sociotécnico". La herramienta probablemente más conocida y aplicada para trabajar la confiabilidad humana es la Técnica para la Predicción de la Tasa de Error Humano (Technique for Human Error Rate Prediction, THERP). THERP es de las primeras técnicas desarrolladas en este campo y se referencia desde el inicio de los sesenta.
Con la THERP es posible predecir las probabilidades de error humano y evaluar el deterioro de un sistema individuo-máquina causado por los errores humanos, los procedimientos, las prácticas de ejecución, así como por otras características del sistema o de la persona que influyen en el comportamiento del mismo. El análisis de la confiabilidad humana nos arrastra a una serie de conclusiones entre las que tenemos las siguientes:
• Los humanos No fallan como las máquinas, sino que cometen errores.
• Las personas no sólo son una fuente potencial de errores, sino que pueden ser un elemento de sobre-confiabilidad dada la capacidad para anticipar, predecir, analizar y actuar sobre los fallos y sus desencadenantes y sobre los propios errores.
• La confiabilidad integral necesaria de un sistema no es de quien la desea o la necesita, sino de quien la hace realidad con su actuación y previsión.
CONFIABILIDAD, MANTENIBILIDAD Y DISPONIBILIDAD
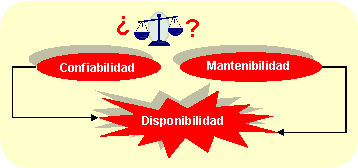
Por Luis Felipe Sexto
Unos de los problemas fundamentales que enfrenta el desarrollo de la confiabilidad de los activos de una empresa, es la mentalidad de solución de problemas que domina el pensamiento de todos aquellos que tienen la autoridad y la responsabilidad para cambiar el estado de cosas. En no pocas ocasiones se tiene a la corrección (que no a la acción correctiva) como paradigma de buenas prácticas de mantenimiento.
Se trata del modelo intelectual que ha dominado la mentalidad de mucha gente (directivos, mantenedores y otros) durante décadas. Independientemente de la existencia de principios, tecnologías y positivas experiencias que se han desechado por subestimación o sobrestimación, al pensarse que son improcedentes de llevar a la realidad empresarial “por no ajustarse a nuestra cultura”. En algunos casos en realidad no se ajustan a las prácticas impuestas y que no se quieren abandonar.
La disponibilidad es la probabilidad de que un activo realice la función asignada cuando se requiere de ella. La disponibilidad depende de cuán frecuente se producen los fallos en determinado tiempo y condiciones (confiabilidad) y de cuánto tiempo se requiere para corregir el fallo (mantenibilidad). De modo que la mantenibilidad queda definida como la probabilidad de que un activo (o conjunto de activos) en fallo, sea restaurado a su estado operativo, dentro de un tiempo determinado, cuando la acción de corrección se efectúa acorde a los procedimientos establecidos por la empresa.
Las fórmulas de confiabilidad formales consideran suposiciones que no siempre resultan válidas para el análisis. Por ello se precisa el estudio cuidadoso para seleccionar los modelos adecuados que reflejen aceptablemente la realidad. Se observa en el esquema que determinado grado de disponibilidad será el resultado del comportamiento de la confiabilidad y la mantenibilidad del activo. ¿Convendrá invertir en mejorar la confiabilidad o la mantenibilidad para lograr un objetivo de disponibilidad? Habrá que valorar en cada caso.
Preciso es reconocer que una intervención, sea reparación por sustitución o restauración, no tienen que necesariamente devolver al activo, o sistema, a un nivel de confiabilidad igual, o presumiblemente superior, al que tenía cuando nuevo. Existen diferentes estados en que puede quedar un activo después de labores preventivas o correcciones. Un activo puede manifestarse en cualquiera de las siguientes situaciones:
- Tan bueno como nuevo.
- Mejor que antes de fallar, pero peor que nuevo.
- Mejor que nuevo.
- Tan malo como antes de fallar.
- Peor que antes de fallar.